Commentaires
Intégrer Elasticsearch 6 dans votre application Symfony 4
Depuis l'article du même nom écrit en
2013, beaucoup de choses ont bougé dans l'écosystème, aussi bien côté Elasticsearch que Symfony.
Aujourd'hui Elasticsearch est très utilisé en stockage de log, monitoring et analyses statistiques, et toujours
bien sûr en outil de recherche full-text. Mais attention, il n'est qu'un outil et sans
maîtrise, sa puissance n'est rien ©.
Cet article s'adresse à vous si vous avez fait le choix d'Elastic et que vous souhaitez partir du bon pied ou
valider son implémentation dans une application Symfony 4.

Elasticsearch ? Jamais entendu parlé !
Cette section s'adresse aux lecteurs qui ne connaissent pas le moteur !
Elasticsearch est un index de recherche gratuit et Open Source développé en Java.
Semblable à une base de données NoSQL, il a la
particularité d'indexer toutes les données de vos documents, via Lucene. Un document y est représenté en
JSON, et la communication entre le moteur et votre application se fait en HTTP, ce
qui le rend compatible avec n'importe quelle infrastructure.
Les recherches se font avec un Query DSL lui aussi en JSON.
Il permet de réaliser des recherches complexes, imbriquées, scriptées et toutes sortes d'opérations classiques : pagination, highlight, statistiques etc.
Son intérêt est d'être très rapide et d'être très facilement distribuable sur plusieurs machines. Il est
aussi capable de calculer des statistiques, et dispose de toute une suite logicielle complémentaire (tableaux de bord,
machine learning, hébergement…).
Aujourd'hui il est mis en place dans de très nombreux projets Web, car sa souplesse permet d'implémenter
pratiquement tout.
Quelle librairie PHP choisir ?
Il existe de nombreuses librairies et bundles pour intégrer Elasticsearch dans Symfony. Il y a 4 ans je recommandais
FOSElasticaBundle, le choix n'est plus aussi simple aujourd'hui.
-
elasticsearch/elasticsearch : Le client
PHP officiel, développé par les équipes d'Elastic. Il est bas niveau, c'est-à-dire qu'il va très
bien gérer l'ensemble des API et des appels HTTP mais vous devez produire les JSON de recherche vous même.
Son gros point fort c'est sa documentation
qui est la seule à être complète. C'est aussi la seule librairie qui est compatible à 100% avec
Elasticsearch 61 ;
-
ruflin/elastica : Librairie d'abstraction objet
pour l'ensemble des API et requêtes d'Elasticsearch. Elle permet de manipuler des objets PHP plutôt que
des tableaux pour créer les requêtes de recherche en JSON. Elle s'occupe aussi de communiquer avec le client
officiel (même si ce n'est pas encore parfait) ;
-
ongr/elasticsearch-dsl : Cette librairie est
proche d'Elastica, elle modélise l'ensemble des clauses du Query DSL et utilise la librairie officielle
comme support HTTP. Sa documentation est très complète et un
bundle est aussi disponible. L'interface est
différente et nécessite de passer par des constructeurs et des méthodes très génériques
(
addParameter), ce qui la place en dessous d'Elastica dans mon cœur ;
-
friendsofsymfony/elastica-bundle :
il s'agit du bundle le plus connu, il embarque Elastica et y ajoute toute la glue pour Symfony : écouteurs d'événements,
commandes de gestion, repositories, configuration et support complet de Doctrine. Par contre il n'est pas
parfait : accumulation de gros retards sur Elastica, très peu de versions publiées (La version 5 du
bundle vient enfin de sortir, merci
Tobion !), tentative de valider la configuration d'Elasticsearch vaine et source d'incompatibilité…
Il s'agit d'un bundle très pratique pour débuter et pour les projets de taille modeste. Sa compatibilité
transparente avec Doctrine permet de récupérer des entités plutôt que les JSON du moteur, et de pousser
automatiquement les modifications de votre base de données dans le moteur. Sur des projets plus gros ou
contraignants il est cependant préférable de ne pas utiliser ces fonctionnalités pour des raisons de performances et
de charge - elle font la promotion de mauvaises pratiques. Implémenter soi-même Elasticsearch permet de mieux
coller aux spécificités de votre projet.
Vous l'aurez compris, Elastica est une référence. Il est simple, plutôt complet et ne va pas
nous limiter dans nos actions. Il existe des centaines de paquets
pour communiquer avec Elasticsearch, mais souvenez-vous qu'à la fin il ne s'agit que d'une API HTTP.
Nous allons étudier dans cet article l'implémentation idéale pour une application de type blog, mais vous
pourrez l'adapter simplement pour d'autres besoins.
Exemple d'implémentation
Installer la démo de Symfony 4 et Elastica
Pour notre exemple nous utiliserons l'application démo de
Symfony : il s'agit d'un blog avec interface d'administration, commentaires et recherche ! Nous installons aussi les dépendances de base :
$ composer create-project symfony/symfony-demo
$ composer require maker
$ composer require ruflin/elastica
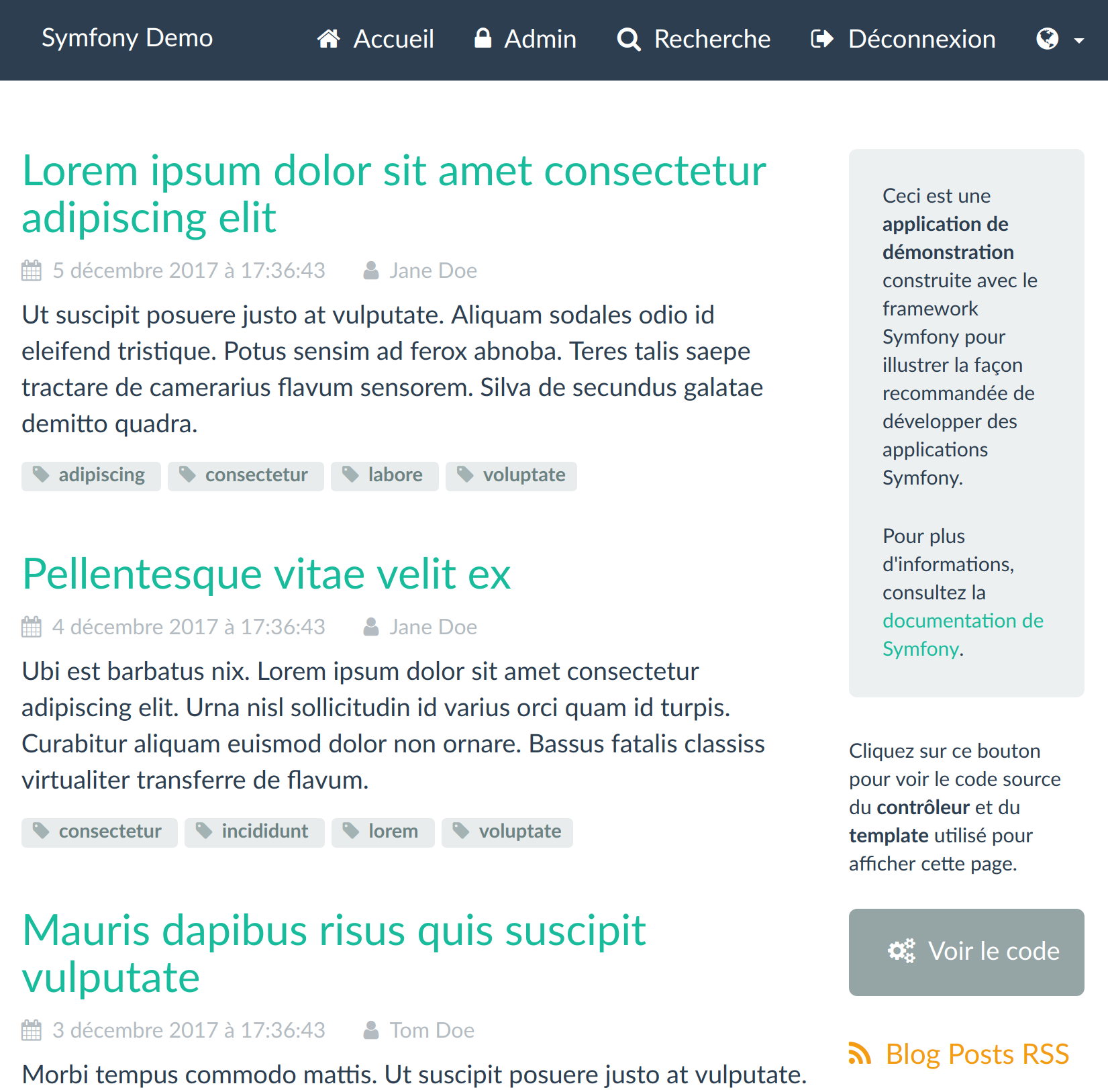
Cette application expose une page de recherche fonctionnant avec une requête SQL
classique en LIKE dans les titres de page :
/**
* @Route("/search", name="blog_search")
* @Method("GET")
*/
public function search(Request $request, PostRepository $posts): Response
{
// ...
$foundPosts = $posts->findBySearchQuery($query, $limit);
$results = [];
foreach ($foundPosts as $post) {
$results[] = [
'title' => htmlspecialchars($post->getTitle()),
'date' => $post->getPublishedAt()->format('M d, Y'),
'author' => htmlspecialchars($post->getAuthor()->getFullName()),
'summary' => htmlspecialchars($post->getSummary()),
'url' => $this->generateUrl('blog_post', ['slug' => $post->getSlug()]),
];
}
return $this->json($results);
}
// PostRepository.php
foreach ($searchTerms as $key => $term) {
$queryBuilder
->orWhere('p.title LIKE :t_'.$key)
->setParameter('t_'.$key, '%'.$term.'%')
;
}
Le code fait actuellement appel à la base de donnée via PostRepository::findBySearchQuery, nous allons
utiliser Elasticsearch à la place !
-
Les temps de réponse ne seront plus proportionnels à la quantité d'articles ;
-
La recherche sera plus fine, avec support des pluriels, des racines de mot, etc. ;
-
Nous pourrons trier les réponses par pertinence contrairement à la requête SQL.
Installer Elasticsearch
Je ne ferai ici pas mieux que la documentation
officielle d'Elastic. Mais si vous voulez allez vite :
version: '2'
services:
# Blablabla, ngnix et PHP si vous voulez
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:6.0.1
environment:
- cluster.name=demo
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 9200:9200
kibana:
image: docker.elastic.co/kibana/kibana:6.0.1
links:
- elasticsearch
ports:
- 5601:5601
Rien de plus simple qu'un petit docker-compose up 😜 !
Créer l'index et le mapping
Avant de pouvoir faire des recherches, nous devrons indexer les articles. Cela implique aussi de créer un index
et de déclarer un mapping (le moteur permet de se passer de
la création de l'index, grace à son mapping
automatique, que je vous recommande fortement de désactiver !).
Un mapping est simplement la déclaration des champs de votre document JSON - est-ce du texte, du booléen... - et la
configuration de l'index inversé : souhaitez-vous analyser ce texte ? Cette date ? Ce slug ? Pour chaque champ
vous devez prendre une décision en fonction de vos besoins :
-
Allez-vous faire des recherches dans ce champ ?
-
Allez-vous faire des statistiques ? Des recherches binaires ?
-
Connaissez-vous la langue du contenu ?
Ce mapping doit être déclaré à la création de l'index et il s'envoie sous la forme d'un JSON à
Elasticsearch ; je déconseille cependant de stocker ce mapping au format JSON dans votre code :
-
Vous ne pourrez pas le rendre dynamique ;
-
Vous ne pouvez pas y mettre de commentaires ;
-
Ce n'est pas une syntaxe faite pour être écrite à la main !
Préfèrez donc le YAML ou le PHP pour configurer votre mapping. Nous allons utiliser cette configuration :
settings:
index:
# single node, no sharding
number_of_shards: 1
number_of_replicas: 0
mappings:
articles:
dynamic: false # disable dynamic mapping
properties:
title: &en_text
type: text
analyzer: english
summary: *en_text
author: *en_text
content: *en_text
Vous trouvez ici la configuration de l'index et la déclaration du mapping de notre "article". Remarquez
l'utilisation d'ancre YAML, bien pratique pour ne pas dupliquer une déclaration ! Nous
précisions à Elasticsearch qu'il faut utiliser l'analyzer
english sur les champs title,
summary, author et content.
Tous les autres champs seront ignorés grace à l'option dynamic.
Exploiter ce document pour créer l'index se fait très simplement avec une classe dédiée à la construction d'Index :
namespace App\Elasticsearch;
use Elastica\Client;
use Symfony\Component\Yaml\Yaml;
class IndexBuilder
{
private $client;
public function __construct(Client $client)
{
$this->client = $client;
}
public function create()
{
// We name our index "blog"
$index = $this->client->getIndex('blog');
$settings = Yaml::parse(
file_get_contents(
__DIR__.'/../../config/elasticsearch_index_blog.yaml'
)
);
// We build our index settings and mapping
$index->create($settings, true);
return $index;
}
}
Pour que notre classe Client soit injectée nous l'avons déclarée manuellement :
services:
Elastica\Client:
$config:
host: 'elasticsearch' # ou 127.0.0.1
Indexer les articles
Avec Elastica, nous devrons créer des Elastica\Document et les envoyer dans notre Elastica\Index.
Pour ce faire nous utiliserons la méthode addDocuments et non pas addDocument ; la
différence est de taille, car la première exploite la BULK API pour
envoyer tous vos documents en un seul appel HTTP, alors que la seconde fera un appel par document et sera donc
beaucoup plus longue.
L'autre point d'importance concernant vos Document est l'ID : il est facultatif dans Elasticsearch mais
si vous voulez retrouver vos articles de blog un jour pour les mettre à jour... Définissez-le à la main !
namespace App\Elasticsearch;
use App\Entity\Post;
use App\Repository\PostRepository;
use Elastica\Client;
use Elastica\Document;
use Symfony\Component\Routing\Generator\UrlGeneratorInterface;
class ArticleIndexer
{
private $client;
private $postRepository;
private $router;
public function __construct(Client $client, PostRepository $postRepository, UrlGeneratorInterface $router)
{
$this->client = $client;
$this->postRepository = $postRepository;
$this->router = $router;
}
public function buildDocument(Post $post)
{
return new Document(
$post->getId(), // Manually defined ID
[
'title' => $post->getTitle(),
'summary' => $post->getSummary(),
'author' => $post->getAuthor()->getFullName(),
'content' => $post->getContent(),
// Not indexed but needed for display
'url' => $this->router->generate('blog_post', ['slug' => $post->getSlug()], UrlGeneratorInterface::ABSOLUTE_PATH),
'date' => $post->getPublishedAt()->format('M d, Y'),
],
"article" // Types are deprecated, to be removed in Elastic 7
);
}
public function indexAllDocuments($indexName)
{
$allPosts = $this->postRepository->findAll();
$index = $this->client->getIndex($indexName);
$documents = [];
foreach ($allPosts as $post) {
$documents[] = $this->buildDocument($post);
}
$index->addDocuments($documents);
$index->refresh();
}
}
Vous remarquerez que indexAllDocuments accepte un $indexName : il est très important
pour la suite, quand vous aurez plusieurs versions de votre index simultanément en production !
Remarquez aussi que nous envoyons dans l'index des champs non indexés (car non présents dans le
mapping), c'est voulu ! Ils seront nécessaires pour l'affichage de nos résultats mais pas pour nos recherches. Sentez-vous libre d'ajouter autant de champs que vous le voulez s'ils ne sont pas indexés.
⚠️ : Cet indexeur ne gère pas les erreurs et le refresh_interval ! Voir à la fin de l'article.
Un peu de glue !
Nous allons développer une commande Symfony qui crée l'index et l'alimenter avec Elastica (bien sûr on se fait aider par MakerBundle !).
$ ./bin/console make:command elastic:reindex
namespace App\Command;
use App\Elasticsearch\ArticleIndexer;
use App\Elasticsearch\IndexBuilder;
use Symfony\Component\Console\Command\Command;
use Symfony\Component\Console\Input\InputInterface;
use Symfony\Component\Console\Output\OutputInterface;
use Symfony\Component\Console\Style\SymfonyStyle;
class ElasticReindexCommand extends Command
{
protected static $defaultName = 'elastic:reindex';
private $indexBuilder;
private $articleIndexer;
public function __construct(IndexBuilder $indexBuilder, ArticleIndexer $articleIndexer)
{
$this->indexBuilder = $indexBuilder;
$this->articleIndexer = $articleIndexer;
parent::__construct();
}
protected function configure()
{
$this
->setDescription('Rebuild the Index and populate it.')
;
}
protected function execute(InputInterface $input, OutputInterface $output)
{
$io = new SymfonyStyle($input, $output);
$index = $this->indexBuilder->create();
$io->success('Index created!');
$this->articleIndexer->indexAllDocuments($index->getName());
$io->success('Index populated and ready!');
}
}
Tout est prêt, nous créons l'index avec notre IndexBuilder, puis nous y envoyons tous les articles
via ArticleIndexer :
$ ./bin/console elastic:reindex
Vous pouvez vous rendre dans Kibana et vérifier que tout est en ordre :
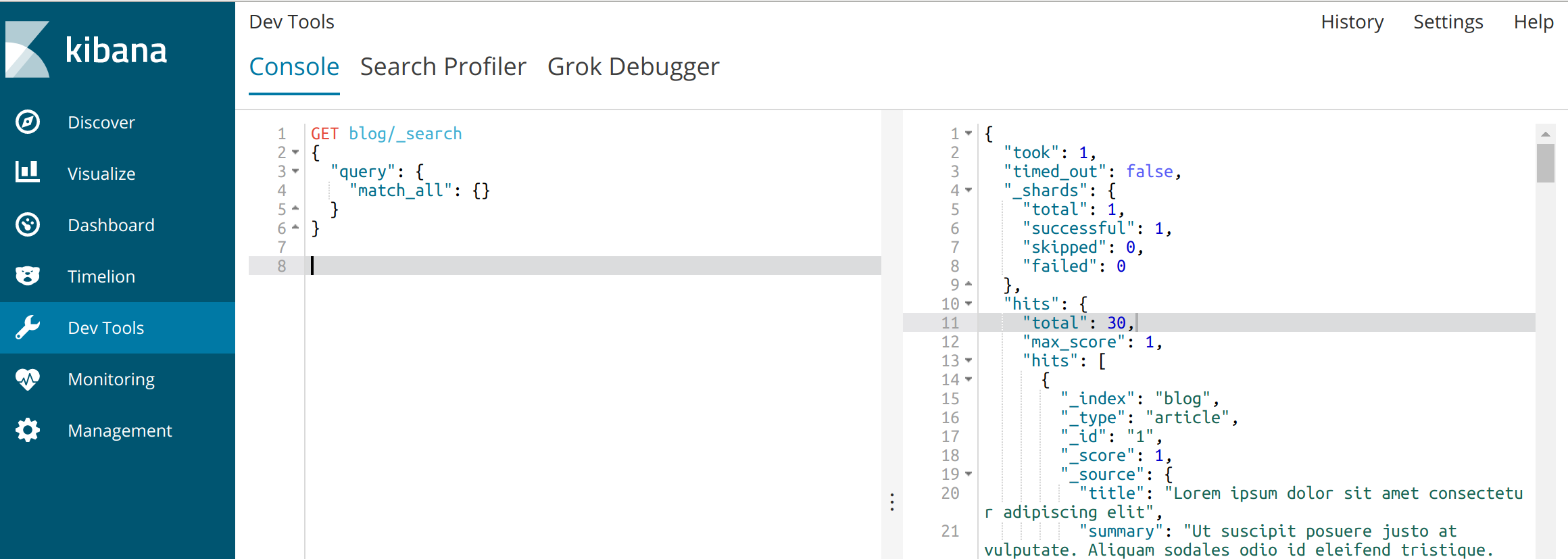
Nos documents Elasticsearch ressemblent à cela :
{
"_index": "blog",
"_type": "article",
"_id": "13",
"_source": {
"title": "Sed varius a risus eget aliquam",
"summary": "Ut suscipit posuere justo at ...",
"author": "Tom Doe",
"content": "Lorem ipsum dolor sit amet consectetur...",
"url": "/en/blog/posts/aliquam-sodales-odio-id-eleifend-tristique",
"date": "Nov 27, 2017"
}
}
Le _source contient l'ensemble des champs envoyés, même si seuls les 4 premiers champs sont
mappés et indexés.
Rechercher dans les articles
Avec l'aide de la console Kibana, nous allons maintenant créer notre requête de recherche. Il n'existe pas de
requête parfaite et l'exercice est toujours délicat, mais essayez toujours d'avoir un bon compromis entre
collecte et pertinence :
-
Avoir un maximum de documents (être très permissif sur les coquilles...) ;
-
Ajouter des critères de pertinence pour que les premiers résultats soient les plus précis.
Nous n'avons pas la place aujourd'hui d'approfondir ces sujets, et je vous renvoie donc vers cet article :
construire un analyzer Français.
Ici la requête sera toute simple ! Nous souhaitons rechercher dans les champs textuels et donner un peu plus de poids au
titre de l'article.
GET blog/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "Aliquam erat volutpat",
"fields": [
"title^4",
"summary",
"content",
"author"
]
}
}
]
}
}
}
Pour traduire cette recherche Elasticsearch en objet Elastica, la technique est d'aller de droite à gauche dans l'imbrication.
Nous commençons par une clause MultiMatch, que nous passons à l'option must de la
clause Bool, que nous passons à l'objet Query. Ce qui donne :
use Elastica\Query;
use Elastica\Query\BoolQuery;
use Elastica\Query\MultiMatch;
$match = new MultiMatch();
$match->setQuery($query);
$match->setFields(["title^4", "summary", "content", "author"]);
$bool = new BoolQuery();
$bool->addMust($match);
$elasticaQuery = new Query($bool);
Pour lancer cette recherche dans Elasticsearch nous réécrivons donc une partie du contrôleur étudié dans l'introduction :
$elasticaQuery->setSize($limit);
$foundPosts = $client->getIndex('blog')->search($elasticaQuery);
$results = [];
foreach ($foundPosts as $post) {
$results[] = $post->getSource();
}
L'action complète :
/**
* @Route("/search", name="blog_search")
* @Method("GET")
*/
public function search(Request $request, Client $client): Response
{
if (!$request->isXmlHttpRequest()) {
return $this->render('blog/search.html.twig');
}
$query = $request->query->get('q', '');
$limit = $request->query->get('l', 10);
$match = new MultiMatch();
$match->setQuery($query);
$match->setFields(["title^4", "summary", "content", "author"]);
$bool = new BoolQuery();
$bool->addMust($match);
$elasticaQuery = new Query($bool);
$elasticaQuery->setSize($limit);
$foundPosts = $client->getIndex('blog')->search($elasticaQuery);
$results = [];
foreach ($foundPosts as $post) {
$results[] = $post->getSource();
}
return $this->json($results);
}
Bien sûr dans un projet plus complet vous voudrez mutualiser les clauses de recherche, vous pouvez vous inspirer
des repository Doctrine.
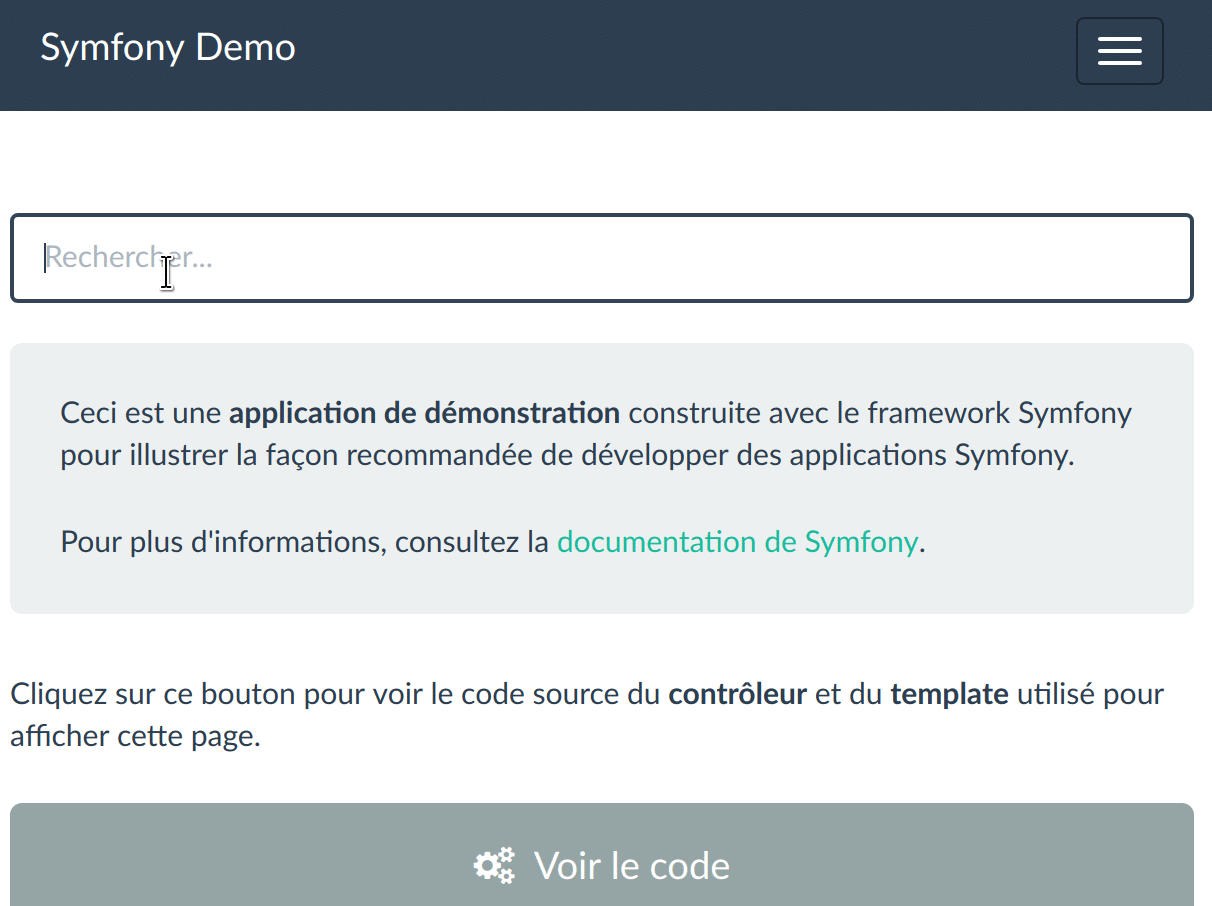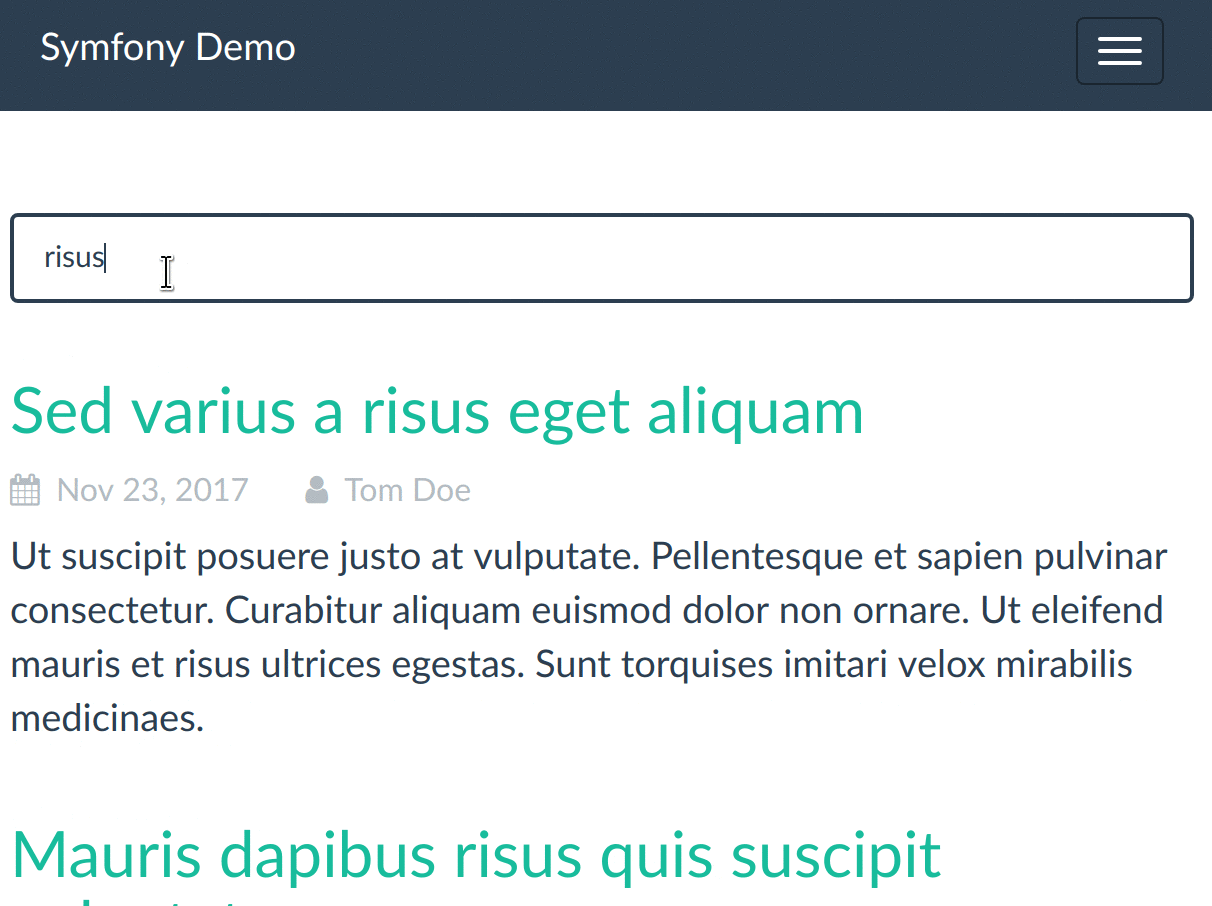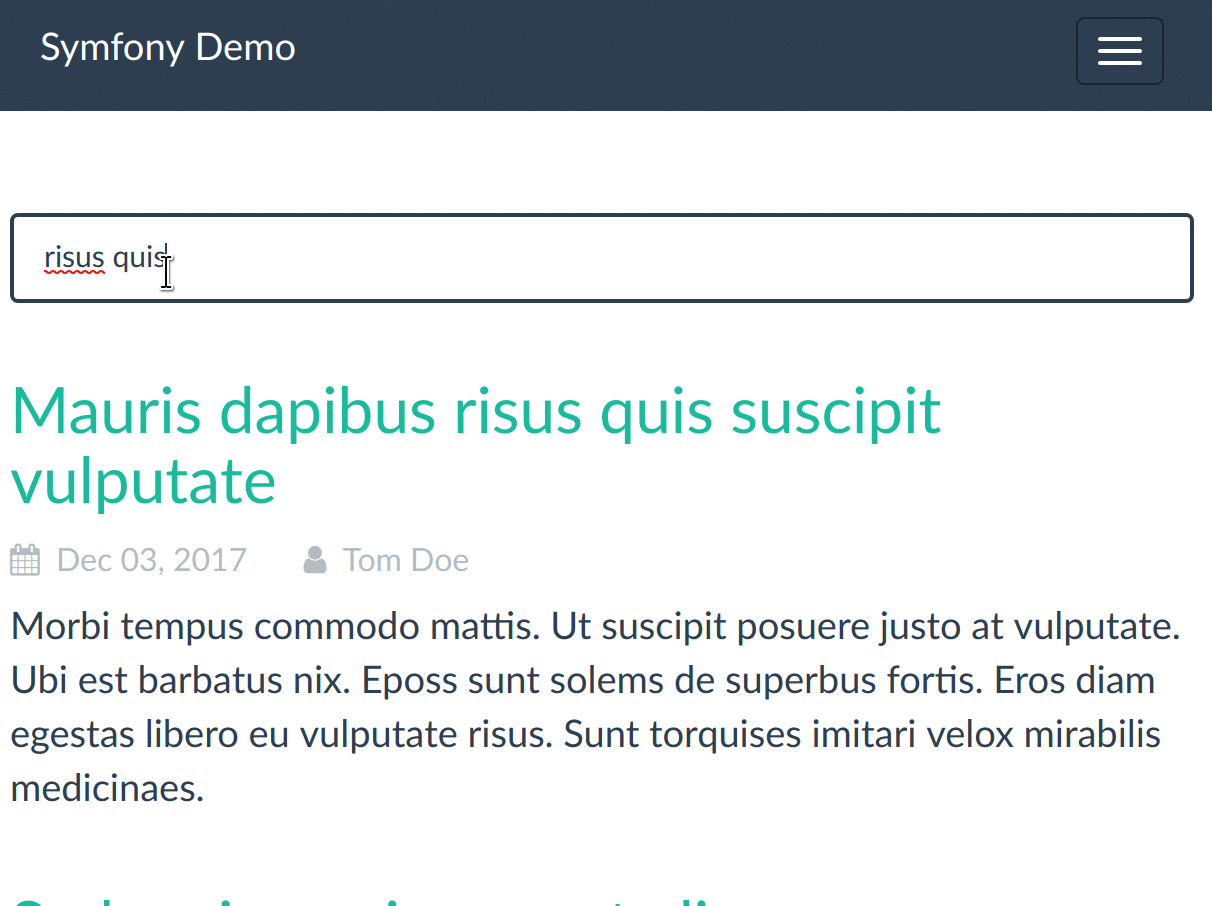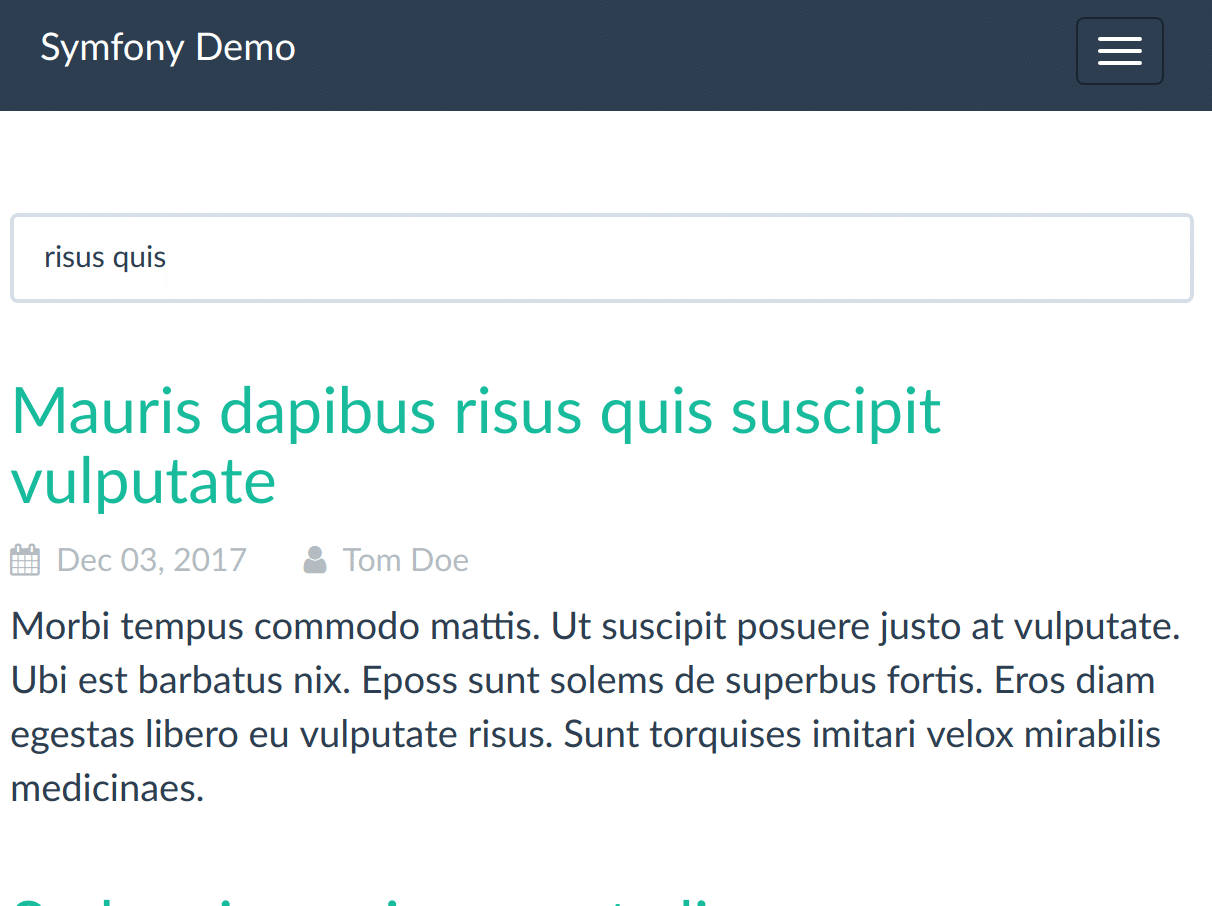
Et voilà notre recherche branchée sur Elasticsearch :
L'outillage et les améliorations nécessaires
Pour les besoins de l'article notre Indexer est volontairement simplifié ; mais dans le monde
réel vous devrez gérer plusieurs choses :
-
Réduire le
refresh_interval lors d'une indexation massive ($index->getSettings()->setRefreshInterval('60s');)
;
-
Gérer les bulks plus finement pour envoyer des paquets de taille ajustable, et gérer les opérations de
suppression ;
-
Gérer les erreurs des requêtes
_bulk : l'API répond toujours 200 sur ce endpoint et c'est à vous de lire
la réponse...
En production vous devrez aussi gérer les mises à jour de mapping. Pour ce faire vous aurez besoin de versionner vos index et d'utiliser des alias pour faire pointer votre applicatif vers le bon
index.
Mettre à jour le mapping signifie aussi ré-indexer vos contenus ! Si vos JSON ne changent pas, automatisez le tout
avec la Reindex API :
$indexManager->slowDownRefresh($newIndex);
$reindex = new Reindex($oldIndex, $newIndex, [
'wait_for_completion' => true,
'timeout' => '30s',
]);
$reindex->run();
$newIndex->refresh();
$indexManager->speedUpRefresh($newIndex);
Ce code permet d'envoyer tous les documents d'un index se faire indexer dans un autre index, vous
économiserez tout le temps que prendrait votre applicatif à re-générer les documents !
Une fois ce nouvel index alimenté vous devrez déplacer un alias sans interruption, comme ceci :
$data = ['actions' => []];
$data['actions'][] = ['remove' => ['index' => '*', 'alias' => 'blog_search']];
$data['actions'][] = ['add' => ['index' => 'blog_v7', 'alias' => 'blog_search']];
return $this->client->request('_aliases', Request::POST, $data);
La gestion d'index par alias est un must-have en production, je vous invite à lire cette documentation pour
en apprendre davantage.
Outillez votre infrastructure : j'ai vu trop de développeurs écrire leurs requêtes
dans Postman, Sense ou Curl ! Installez Kibana et vous ne le regretterez pas. Profitez-en pour installer Cerebro, qui remplace Kopf, Head et tous les
plugins "sites" qui ont disparu d'Elasticsearch en version 5.
Pour finir, ne réinventez plus la roue, il est inutile de créer des dizaines de commandes Symfony pour gérer
votre cluster, je vous recommande plutôt de prendre en main Curator,
qui est un outil officiel !
J'espère que cet article vous aura aidé à y voir plus clair sur les tenants et aboutissants de l'utilisation
d'Elasticsearch dans vos projets, et je terminerai en vous souhaitant de bonnes fêtes !
