Commentaires
Best practices pour vos APIs REST HTTP avec Symfony2
C'est un exercice assez difficile de faire un nouvel article au sujet de la
création d'APIs REST, tant ce sujet a déjà été largement traité, que ce soit
dans
l'écosystème
Symfony / PHP
ou en dehors.
Néanmoins, il arrive encore trop souvent que, par méconnaissance ou par
facilité, des développeurs créent des Web Services « pseudo-REST »,
collectionnant un nombre plus ou moins important de mauvaises pratiques :
couplage fort à des besoins métiers, manque de formalisation ou de
consistance, absence de versionning ou mauvaise utilisation des méthodes
HTTP etc.
Cet article n'a pas pour objectif d'expliquer une nouvelle fois ce qu'est
REST, mais plutôt de donner les clés des bonnes pratiques REST, et d'amener
le développeur à se poser les bonnes questions lors de la création de ses
premiers services : l'avenir lui dira « merci » !
Avant de commencer, fixons quelques définitions :
-
une API
(aka « Application Programming
Interface ») est une interface de manipulation à destination des
machines;
-
Lorsqu'on parle d'une « API REST HTTP », on parle d'une application Web
proposant un ou plusieurs Web Services respectant le formalisme REST;
-
REST est un style
d'architecture proposant l'exposition de ressources (on parle aussi
d'entités).
Cet article traite le sujet des APIs REST HTTP selon trois axes principaux :
- accéder à l'API ;
- la formaliser ;
- l'exploiter.
Accéder à l'API
Verbes HTTP
Concrètement, une API REST HTTP expose des représentations de ressources
(des articles, des personnes, des poneys,
etc.), et permet de les manipuler (les lister, en créer, en modifier, en
supprimer, etc.) par le biais de requêtes HTTP.
L'adéquation entre REST et HTTP suggère assez naturellement l'emploi des
méthodes HTTP
pour la réalisation d'opérations courantes :
- lister des entités :
GET
- créer une entité :
POST
- modifier une entité :
PUT (ou PATCH, suivant que la mise à jour est complète ou partielle)
- supprimer une entité :
DELETE
Concrètement, si votre API permet d'appeler un Web Service
http://example.tld/creer_article par le biais de la méthode
GET, il y a de bonnes chances pour que vous soyez dans le faux
:-)
Plan d'adressage
Un second élément marquant d'une API REST HTTP est, évidemment, l'ensemble
des URLs qui sont exposées (ce que l'on nomme souvent le « plan
d'adressage » de l'API).
Même si, en soit, REST ne force pas un style d'URIs particulier (rien ne
vous empêche d'utiliser des noms d'URLs abscons pour exposer vos
ressources), l'usage et la pratique montrent qu'un plan d'adressage clair,
lisible et consistant favorisent l'adoption d'une API, sa facilité de
compréhension et d'utilisation.
Pour exposer des ressources, vous choisirez donc d'exposer des urls courtes,
nommées suivant le type de ressource exposée :
http://domain.tld/ponieshttp://domain.tld/ponies/118- etc.
Suivant le fameux principe « Cools URIs don't change »,
choisissez évidemment des URLs agnostiques du point de vue de la technologie
(ie., pas de « .php » dans l'url) ou de tout autre élément
susceptible de changer dans le temps.
Exposer des URLs Restful est une tâche assez aisée, pour peu que
l'on s'attache à adopter une démarche rigoureuse et consistante. Afin de
nous aider dans notre quête, le bundle
FOSRestBundle
permet d'automatiser un grand nombre de tâches liées à la conception d'APIs
REST. Un de ses atouts majeurs est qu'il permet de générer des routes
automatiquement (et les urls associées) à partir de noms d'actions dans les
contrôleurs.
Pour cela, il suffit de déclarer au routeur de charger des routes de type
rest depuis le contrôleur de notre API :
# le routing.yml de notre bundle
ponies:
type: rest
resource: Pony\ApiBundle\Controller\PoniesController
Et dans le contrôleur correspondant, il suffit juste d'ajouter des
actions...
<?php
namespace Pony\ApiBundle\Controller;
class PoniesController
{
public function getPoniesAction()
{
}
public function postPoniesAction()
{
}
public function getPonyAction($slug)
{
}
public function commentPonyAction($slug)
{
}
}
..., et les routes correspondantes sont automatiquement créées, avec les
restrictions :
-
get_ponies :
GET
/ponies
-
post_ponies :
POST
/ponies
-
get_pony :
GET
/ponies/{slug}
-
comment_pony :
PATCH
/ponies/{slug}/comment
Il ne reste « plus qu'à » remplir les contrôleurs avec la logique que doit
suivre l'API \o/
Formaliser l'API
Une API REST HTTP permet, comme son nom l'indique, d'accéder à des
ressources en employant le style d'architecture et en dialoguant par le
biais du protocole HTTP : le client REST émet donc des requêtes
HTTP vers le serveur d'API, qui lui répond par le biais de réponses
HTTP.
Rien de neuf ici, encore une fois, faisons juste un rappel. Une
réponse HTTP
est composée de trois éléments :
-
un code de statut, qui indique de manière numérique le résultat de la
tentative de traitement de la requête ;
-
un ensemble d'en-têtes (des « headers »), qui fournissent au
client des informations supplémentaires ;
- le corps de la réponse.
Définir une API REST HTTP passe donc par la définition du contenu de ces
trois éléments.
Codes de statut
Encore une fois, l'usage de
codes de statuts HTTP
adaptés est une bonne pratique pour des APIs RESTful. Si votre API répond
systématiquement avec un statut HTTP 200, qu'il y ait une
erreur ou pas, il y a un sérieux problème parce que vous sous-utilisez les
capacités d'HTTP.
En réalité, de nombreux codes HTTP peuvent être employés par des APIs HTTP :
-
200 si la requête a pu être traitée avec succès ;
-
des variantes sont
201 ou 204, suivant
l'opération qui a été demandée au serveur ;
-
304 si le document demandé n'a pas été modifié depuis la
dernière fois que le client l'a demandé ;
-
400, 401, 402, 403,
404, 406, 409, 429
sont des codes d'erreur adaptés à différentes situations d'erreur
d'utilisation de l'API ;
-
500 ou 503, suivant que votre application
subit un problème technique, est indisponible temporairement
(maintenance).
L'ensemble de ces codes de statut est documenté clairement dans les RFCs.
Vous pouvez aussi consulter cette page,
qui liste l'ensemble des codes de statut que vous êtes susceptibles
d'employer dans vos APIs.
Symfony est un framework extrêmement flexible de ce point de vue ; on peut
aisément définir les codes de statut à associer à une réponse HTTP :
$response->setStatusCode(Response::HTTP_OK);
Vous pouvez voir l'ensemble des codes de status de la RFC de HTTP dans la
classe Symfony\Component\HttpFoundation\Response.
Contenu et fonctionnalités
Les trois chapitres précédents sont fondamentaux pour la formalisation de
votre API REST mais, finalement, ils correspondent peu ou prou à ce que vous
avez déjà pu lire ailleurs au sujet de REST, et ils s'appliquent à toute API
REST bien faite.
La structure du corps de la réponse, et les fonctionnalités exposées par
votre API, elles, sont propres à chaque situation. C'est au moment de la
conception de votre API que vous devrez faire les choix suivants.
Nommage
C'est une bonne pratique pour votre code, et c'est également une bonne
pratique pour les APIs : exposez des urls, des noms de champs ou des
paramètres en anglais. Cela facilitera l'adoption large de votre API, en ne
faisant pas de la langue une barrière forte. Mettons les débats de côté - la
langue française est
malheureusement dépassée dans le domaine du développement informatique,
c'est juste un fait : prenez-en acte.
Le contenu du corps de la réponse sera formaté différemment suivant le
format de sérialisation adopté (cf. infra). Choisissez néanmoins
des noms courts, expressifs, non ambigus.
Filtres
Dans le cadre de notre API exposant des poneys, il peut être pratique de ne
vouloir que certains poneys, ceux qui correspondent à certaines contraintes.
Par exemple, on pourrait choisir de ne sélectionner que les poneys dont le
type est « Shetland »,
ou ceux mesurant 1 mètre 40.
Afin de permettre ces fonctionnalités de filtrage, il est nécessaire
d'exposer clairement les filtres disponibles par le biais de l'API :
/ponies?type=shetland/ponies?type=shetland,connemara/ponies?height=140/ponies?type=shetland,connemara&height=140- etc.
Symfony propose un moyen élégant et simple de répondre à cette question, en
s'appuyant sur l'annotation @QueryParam fournie par le
FOSRestBundle :
/**
* @QueryParam(name="height", requirements="\d+", description="Height of the pony in cm.")
* @QueryParam(name="type", description="Type of the pony.")
*/
public function getPoniesAction(ParamFetcher $paramFetcher)
{
// do something !
}
Les filtres les plus fréquemment employés peuvent être exposés sous la forme
d'alias. Par exemple, /articles/published est un alias plus
« user-friendly » que
/articles?publication_status=published.
Vous pouvez aisément créer des alias dans Symfony en utilisant le mécanisme
de routage pour déclarer une route manuellement
Tri
Dans la même veine, il peut être important de permettre d'ordonner les
réponses dans un certain ordre. Votre API doit donc permettre d'ordonner les
résultats, par le biais de paramètres passés au service.
Généralement le tri se fait par le biais d'un paramètre
« sort », parfois accompagné d'un second paramètre
« sort_order », ou précédé du symbole « - » pour indiquer que
le tri doit se faire en ordre inversé :
-
/ponies?sort=type : par ordre de type
alphabétique,
-
/ponies?sort=-height : par ordre de taille
inversé.
Pagination
La mise en place d'une pagination est souvent ignorée et, lorsqu'elle est
traitée, est la plupart du temps assez délicate. Pour reprendre l'exemple de
l'API de poneys, une requête sur /ponies risque de retourner
une grande liste de poneys, et donc de produire un corps de réponse trop
volumineux.
Les APIs ayant des contraintes de performance au même titre que les autres
applications Web, l'approche la plus traditionnelle consiste à mettre en
place une pagination, qui permet de limiter le corps de la réponse à un
certain nombre d'éléments.
Mettre en place une pagination de manière propre ne se fait pas uniquement
en ajoutant un paramètre page dans l'url. Il faut auparavant
répondre aux questions suivantes :
-
est-ce que la taille des pages est paramétrable par l'utilisateur ? Dans
ce cas il sera nécessaire d'ajouter le support d'un paramètre optionnel
de type
page_size.
-
si oui, y a-t-il une taille de page maximale ? Hint : c'est une
bonne idée, pour éviter les dérives du type
?page_size=1000000000
-
à partir d'une page donnée, comment navigue-t-on vers les pages
précédentes et suivantes ?
Pour cette dernière question, il va être nécessaire de parler un peu de
navigabilité, c'est-à-dire de la capacité de notre API à être explorée -
naviguée - par des applications, des programmes.
La manière élégante et respectueuse d'HTTP pour fournir, à partir d'une page
donnée, les liens vers les pages précédentes et suivantes, consiste à
ajouter un en-tête de réponse Link. Par exemple, l'en-tête
Link associée à la page 2 devrait ressembler à :
Link: <https://api.domain.com/ponies?page=1&per_page=100>; rel="first",
<https://api.domain.com/ponies?page=1&per_page=100>; rel="prev",
<https://api.domain.com/ponies?page=3&per_page=100>; rel="next",
<https://api.domain.com/ponies?page=118&per_page=100>; rel="last"
Il suffit donc seulement d'ajouter des en-têtes à la Response
pour traiter correctement cette problématique :
$response->headers->set('Link', $links);
Sérialisation
Formats de sérialisation
Le contenu du corps de la réponse peut être exprimé suivant différents
formats. Si, pendant longtemps, Web Service a rimé avec
« XML »
pour les développeurs, ce n'est heureusement plus le cas : XML n'est pas le
seul format pour servir de manière pertinente des informations
structurées.
Dans l'idéal, une API REST HTTP permet d'exposer les données dans trois
formats :
-
XML, qui a l'avantage d'être une
syntaxe très formelle, structurante, et extensible, mais est en revanche
plutôt verbeux (volumineux), et parfois pénible à lire pour le
développeur ;
-
json
qui, outre l'avantage de la concision, est un format aisément
exploitable en javascript. Attention, certaines distributions ont, pour
des problèmes de licence, récemment
retiré l'extension json,
qui doit désormais être installée séparément (sur Debian, par exemple,
un
$ apt-get install php5-json résoudra le problème) ;
-
MessagePack, un format de
sérialization binaire qui peut permettre de gagner encore quelques bits
supplémentaires. MessagePack peut être disponible très aisément en PHP,
en installant le package PECL associé :
$ pecl install msgpack
Le choix du format de la réponse ne doit pas se faire sur une extension dans l'URL, mais par le biais de l'en-tête de requête Accept, qui permet au client d'indiquer quels sont les types de contenus acceptables en guise de réponse.
Si le client indique qu'il souhaite une réponse au format
application/json, le serveur pourra librement décider d'envoyer
une réponse en application/json, ou répondre par un code de
statut HTTP 406 (Not Acceptable).
Comment tout cela est-il traité avec Symfony ? Encore une fois, le bundle
FOSRestBundle aide énormément.
Suppression des espaces, performance FTW?
Une tentation qui revient fréquemment consiste à vouloir optimiser la taille
de la réponse en supprimant les espaces non-nécessaires. Par exemple, une
réponse sérialisée en XML sera moins volumineuse (en octets) si on retire
tous les sauts de lignes et les caractères d'indentation.
Cette idée est une fausse bonne idée : cela rendra votre API peut aisée à
explorer et examiner pour les développeurs (même si, certes, il existe des
outils pour mettre en forme un flux XML ou json), et le gain sera très
faible, de l'ordre de quelques pour cent seulement. Il vaut mieux placer vos
efforts dans la bonne compréhension des modules de compression de la réponse
qui sont disponibles pour
nginx
ou
Apache
(et la charge serveur associée sera ainsi bien mieux utilisée) !
Navigabilité : HATEOAS or not?
Imaginons que notre API dédiée aux poneys est sensiblement plus complète que
prévu. Par exemple, nous pourrions aussi exposer un Web Service pour les
types de poneys, pour la liste des concours de poneys, pour les
participations de tel ou tel poney à un concours, etc.
Afficher des informations et permettre des interactions en rapport avec un
poney donné peut se faire par différentes approches :
Une première solution consiste à embarquer toutes les informations
nécessaires à l'affichage dans un seul service, eg. :
{
"poney": {
"id": 118,
"name": "Michel",
"type": {
"id": 1,
"name": "Shetland",
"countries": [{
"id": 33,
"name": "France"
},{
"id": 44,
"name": "United Kingdom"
}]
},
"bithdate": "2010-08-23",
"gender": "male",
"contests": [{
"id": 1199,
"name": "IPC 2013 - International Pony Contest 2013",
"location": "Munich, Germany",
"startDate": 2013-10-27,
"endDate": 2013-10-30,
}]
}
}
Corolaire de son avantage, cette solution a évidemment l'inconvénient de
produire des réponses verbeuses, et forcément centrées sur certains cas
d'usage. Le risque, avec cette approche, est de concevoir des APIs aux
réponses plus complexes que nécessaire, et aux performances dégradées par
rapport aux besoins réels.
Une deuxième approche consiste à choisir de revenir aux sources de REST en
se concentrant, pour chaque URL, sur la représentation de la ressource
elle-même, sans se soucier des éléments liés. Dans ce cas, une réponse
pourrait être :
{
"poney": {
"id": 118,
"name": "Michel",
"typeId": 1,
"bithdate": "2010-08-23",
"gender": "male",
"contestIds": [ 1199 ]
}
}
Cette seconde approche est déjà plus intéressante, dans la mesure où elle
permet de récupérer des données de manière atomique, sans courir le risque,
à chaque appel, de récupérer un flux énorme de données.
Cette approche souffre néanmoins de deux limitations principales :
-
comment un client peut-il savoir quelle est l'URL à laquelle il peut
trouver la ressource «
type » pour le poney
« Michel » ? Idem pour le contest dont on nous fournit
l'identifiant 1199 !
-
pour afficher la fiche d'identité complète d'un poney, un client
devra-t-il donc réaliser n requêtes, en fonction de l'activité
de ce poney ?
La première question peut être résolue par une approche
HATEOAS,
qui permet d'exposer les actions ou transitions possibles à partir de la
ressource actuellement exposée, par le biais de lien hypermédias.
La réponse pourrait par exemple devenir :
{
"poney": {
"id": 118,
"name": "Michel",
"typeId": 1,
"bithdate": "2010-08-23",
"gender": "male",
"contestIds": [ 1199 ],
"_links": {
"self": { "href": "/ponies/118" },
"comments": { "href": "/ponies/118/comments" },
"contests": { "href": "/ponies/118/contests" },
"type": { "href": "/types/1" }
}
}
}
Pour être plus précis, il existe actuellement plusieurs syntaxes
(non-normées) pour exprimer des liens entre ressources. Une des plus
utilisée est HAL,
employée pour l'exemple ci-dessous, mais vous pourrez jeter un oeil à
Collection+JSON,
JSON for Linking Data ou encore
JSON API, qui proposent des alternatives
similaires.
Si on utilise bien cette approche sur tous les services exposés par notre
API, un client qui souhaite en exploiter les données pourra le faire sans
avoir une connaissance parfaite du plan d'adressage de notre API. Il n'aura
pas, par exemple, à implémenter la construction de l'URL qui permet
d'accéder aux commentaires associés au poney « Michel » : ce
sont les liens qui lui fourniront cette indication.
L'écosystème Symfony2 montre encore une fois, sur ce point, son dynamisme.
Deux bundles permettent de traiter le problème :
Dans les deux cas, ces bundles procèdent par une association d'annotations
aux entités, permettant de définir quels sont les liens à retourner dans une
sérialisation de l'entité. Par exemple, avec
BazingaHateoasBundle :
<?php
namespace Pony\ApiBundle\Entity;
use JMS\Serializer\Annotation as Serializer;
use Hateoas\Configuration\Annotation as Hateoas;
/**
* Run Pony, run
*
* @Serializer\XmlRoot("pony")
* @Hateoas\Relation("self", href = "expr('/ponies/' ~ object.getId())")
* @Hateoas\Relation("comments", href = "expr('/ponies/' ~ object.getId() ~ '/comments')")
* @Hateoas\Relation("type", href = "expr('/types/' ~ object.getType())")
*/
class Pony
{
private $id;
private $name;
private $type;
private $height;
}
Et au moment de la sérialisation de l'entité, ses liens sont automatiquement
ajoutés :
{
"id": 1,
"name": "John Silver",
"type": "Connemara",
"height": 134,
"_links": {
"self": {
"href": "/ponies/178"
},
"comments": {
"href": "/ponies/178/comments"
},
"type": {
"href": "/types/12"
}
}
}
Versionner son API et anticiper le futur
Une autre problématique fréquente, qui est très souvent oubliée ou négligée,
concerne la maintenance dans le temps d'une API.
Supposons que, une fois notre API de poneys en ligne, plusieurs développeurs
décident de créer des applications Web ou mobiles pour en exploiter le
contenu. Naturellement, ces développeurs vont utiliser l'API dans le
formalisme qu'elle propose à cet instant là.
Or, pour des raisons métier (on fait évoluer le modèle de données pour gérer
un plus grand nombre de métadonnées au sujet des poneys) ou simplement pour
des raisons de refactoring technique, il peut arriver que la structure et le
format d'une API change. Si les changements sont absolument mineurs,
l'impact sur les clients d'API reste mesuré. Mais si les modifications sont
plus profondes, cela peut conduire certains clients à ne plus fonctionner
correctement.
Pour les applications Web clientes, l'impact reste mesuré : il suffit que
leurs développeurs fassent l'effort de mettre à jour pour s'adapter à l'API
modifiée, et tous les utilisateurs finaux ont à nouveau un outil qui
marche.
En revanche, le cas des applications mobiles natives, installées sur les
téléphones des utilisateurs, est plus compliqué, puisque rien ne force (en
tout cas pour le moment) un mobinaute à mettre à jour ses applications. un
utilisateur lambda peut donc, d'un jour à l'autre, constater que son
application ne fonctionne plus, et elle ne fonctionnera pas mieux tant
qu'elle n'aura pas été mise à jour, parce que le format de l'API qu'elle
consomme a changé.
Avouez que ça fait tâche. En résumé, il est donc nécessaire de versionner
vos APIs pour éviter ce genre de problème.
Là encore, il y a plusieurs approches : les approches approximatives ou les
approches plus théoriques et en phase avec HTTP :
-
passer un numéro de version dans l'URL :
http://api.domain.com/ponies/118?version=2.1 ou
http://api.domain.com/2.1/ponies/118
-
employer encore une fois l'en-tête
Accept, afin de préciser
un numéro de version d'API à employer:
Accept: application/json; version=2
L'approche http://api.domain.com/2.1/ponies/118 a l'avantage,
en terme d'architecture, de pouvoir se régler simplement par le déploiement
de plusieurs versions de votre application. Pour les deux autres, en
revanche, il est nécessaire de traiter le versionning au sein d'une seule
instance de votre application. Prévoyez par exemple plusieurs classes de
contrôleur, et un RequestListener en charge de l'extraction de
la version de l'API et de la redirection vers le bon contrôleur.
Quelle que soit l'approche choisie, il arrivera un moment où vous ne pourrez
plus conserver les versions les plus anciennes de vos APIs. Si les
technologies ou le modèle de données sous-jacent change trop, par exemple,
vous ne souhaiterez certainement pas faire l'effort d'adaptation des
anciennes versions de l'API. Ce genre de cas se traite en rendant obsolète
(ie., plus supportée) les versions les plus anciennes de votre API. Il
suffit de prévoir cette obsolescence à l'avance, et d'en prévenir les
utilisateurs afin de leur laisser le temps de migrer sereinement.
Si c'est possible, vous pouvez aussi choisir de rediriger les requêtes avec un code de statut 301 vers une version plus récente du même service, ou simplement répondre par un code de statut d'erreur 410.
Héberger, surveiller, encadrer et documenter
Give me cache, bitch!
Une bonne API REST respecte un principe d'idempotence : deux requêtes
successives produisent la même réponse. Sauf changement dans l'intervalle,
deux appels à l'API avec une même entête Accept pour obtenir la
fiche du poney Michel devront donc produire le même
résultat.
Cela signifie notamment qu'une API REST doit être « stateless »,
c'est-à-dire sans état. Si vous devez gérer des droits d'accès, votre API ne
doit donc pas réagir aux sessions, mais vous devez à la place fournir un
jeton à chaque appel de l'api. Encore une fois, deux écoles s'affrontent :
passer le jeton dans l'URL ou par le biais d'une entête. Et comme toujours,
utiliser une en-tête est plus smart, mais peut être un problème
avec certains clients HTTP peu avancés.
Un gros avantage de ce caractère « stateless », c'est qu'il permet
aisément, du coup, d'associer du cache HTTP à votre API. Suivant les
contraintes métier, vous pourrez choisir d'en restreindre la durée de vie,
mais c'est une bonne idée, pour limiter la charge, de toujours mettre une
durée de cache minimal sur vos APIs. En cas de fort trafic, un cache de 10
secondes peut réellement faire baisser la charge du serveur d'API.
Analyser et grapher les performances
Une API REST HTTP est faite pour être consommée par des clients d'API. Cela
signifie que des systèmes tiers (les « clients ») sont dépendants du temps
de réponse de l'API. Si votre API répond en 10s, les clients qui
l'exploitent souffriront de la latence ainsi introduite, et il y a fort à
parier qu'au final votre API sera jugée peu satisfaisante.
Il n'y a pas de métrique absolue, mais une API devrait répondre le plus
rapidement possible, quelle que soit la requête. Un ordre de grandeur de 20
à 50 ms parait raisonnable.
Mettez en place une suite de tests fonctionnels pour éprouver la solidité de
votre API et valider en continu son bon fonctionnement, et graphez les
performances de votre API. Cela vous permettra de détecter les brusques
ralentissements, ou la lente dégradation des performances au fur et à mesure
que les fonctionnalités s'enrichissent.
Limiter le rythme
Afin de protéger votre API contre les abus - volontaires type
DoS
ou involontaires (un client bogué) - une approche raisonnable peut consister
à limiter le nombre de requêtes autorisées pour un client dans une durée
donnée. Par exemple, vous pouvez vouloir limiter un client à 300 requêtes
par heure.
Pour cela, plusieurs en-têtes HTTP peuvent aider :
-
X-Rate-Limit-Limit permet d'indiquer le nombre d’appels
maximal par tranche de temps (par exemple, une heure) ;
-
X-Rate-Limit-Remaining indique le nombre d’appels encore
disponibles ;
-
X-Rate-Limit-Reset indique l'heure à laquelle les compteurs
seront ré-initialisés.
Par exemple :
X-Rate-Limit-Limit: 7500
X-Rate-Limit-Remaining: 7499
X-Rate-Limit-Reset: 1386256560
Il est possible de mettre en place cette protection au niveau de votre
application - mais cela sera consommateur de ressources - ou directement au
niveau du serveur. Par exemple, nginx propose le module
ngx_http_limit_req_module.
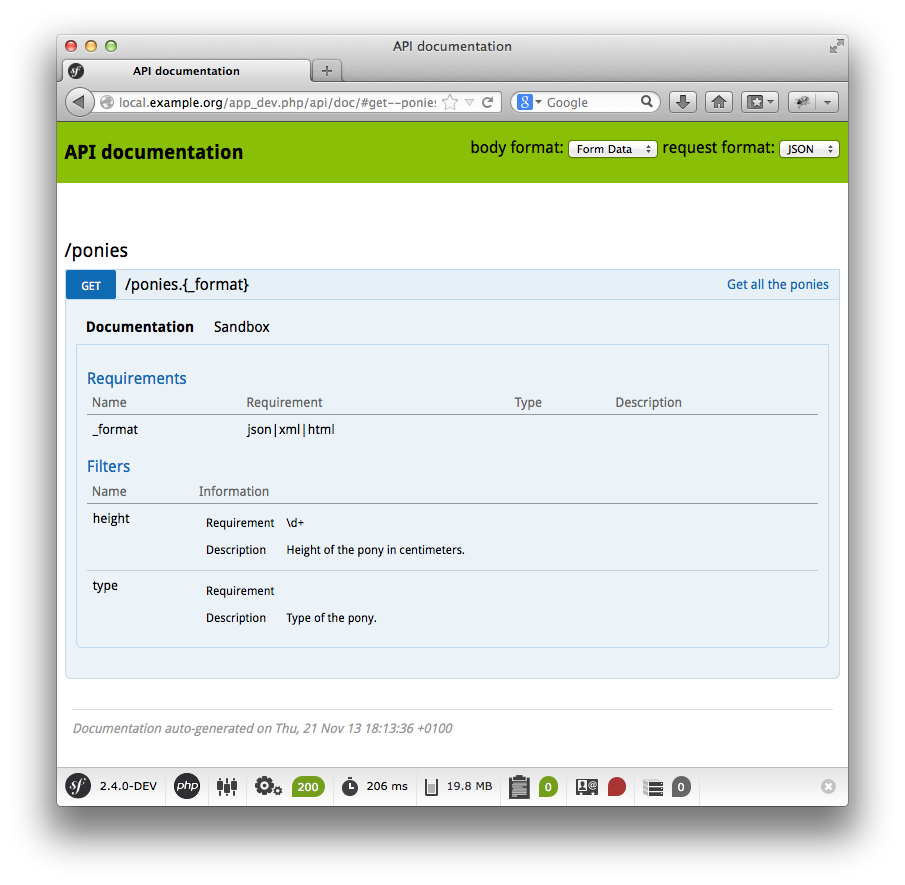
Documenter
C'est le dernier paragraphe de ce (long) article au sujet des APIs REST
HTTP, mais c'est certainement un de ceux que vous devez lire avec le plus
d'attention :-)
Un élément essentiel d'une API est sa documentation. Sans documentation
exhaustive, une API n'a aucune valeur réelle, puisque son utilisation est
sujette à interprétation. Les développeurs d'APIs disposent depuis longtemps
d'outils type
Swagger,
qui permettent d'afficher de jolies pages de documentation d'API.
Le bundle
NelmioAPIDocBundle
est de ce point de vue un must-have : il permet d'exposer
facilement, en quelques minutes, ce type de documentation à vos
utilisateurs. Il suffit d'ajouter une annotation sur les services que vous
souhaitez documenter, et le bundle s'appuie automatiquement sur l'annotation
@QueryParam :
/**
* @QueryParam(name="height", requirements="\d+", description="Height of the pony in centimeters.")
* @QueryParam(name="type", description="Type of the pony.")
*
* @ApiDoc(resource=true, description="Get all the ponies")
*/
public function getPoniesAction(ParamFetcher $paramFetcher)
{
// stuff here
}
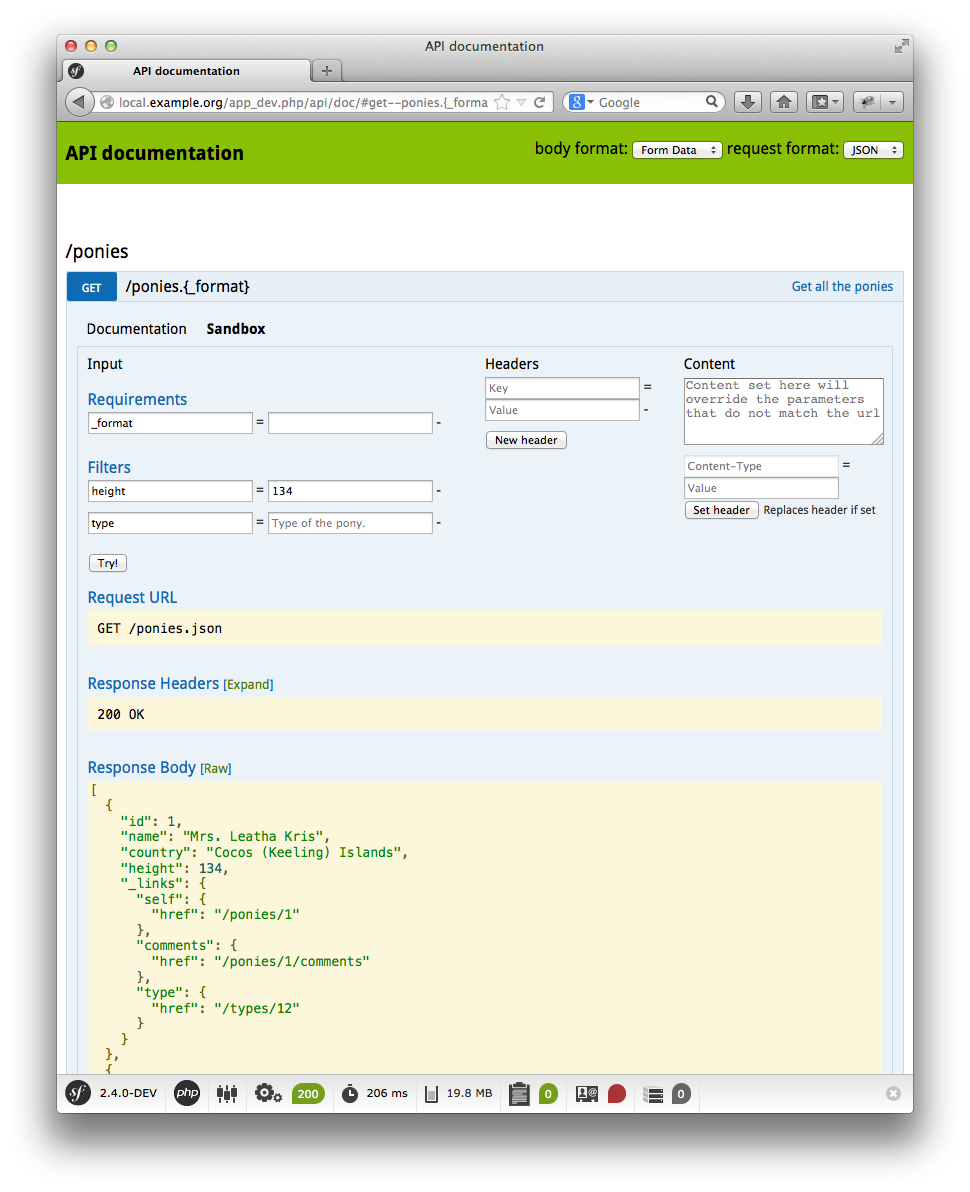
Et vous pouvez même disposer d'un bac à sable, permettant la réalisation
d'opérations sur l'API (tests, etc.) directement depuis la page de
documentation !
N'attendez pas la fin de votre projet pour documenter : vous pouvez le faire
dés le début, et ainsi avancer en parallèle des clients HTTP éventuels,
quitte à bouchonner à l'aide d'outils tiers comme
Apiary.
Bonne APIculture !
